
SQL DDL:インデックス定義
概要
※=索引
本の索引が目的のページを探すのに役立つ様に、
データベースが目的のレコードを探すのに役立つ情報。
・一意でない(重複する)データを持つ行に対して索引を作成すると検索速度が速くなる場合がある。
「索引による速度向上低下」参照
主キー制約列/一意制約列には自動的に索引は作成されている(索引名=制約名)
・索引が無い場合、フルスキャンが行われる。
・索引作成により索引データが作成される。
索引データにはキーの値とそのキーの値を持つ行へのポインタ(ROWID)がが格納され、SELECT時等にこのデータが参照される。
フルスキャン時のディスクのI/O回数 > 索引データの参照回数
の時に速度が向上する。
アクセスパス
SQLがデータベースからデータを取得する手順
統計情報
・テーブルの行数、
・インデックス
等、実データとは別の領域に保存され、別の容量を必要とする。
オプティマイザ
DBMS(DataBaseManagementSystem)において、
SQL・統計情報を解釈し、アクセスパスを決定するエンジン
フルスキャン
インデックスを用いず、全レコードを先頭から順番に検索すること。
B-ツリーインデックス
BalancedTree
探索木方式。
特に指定しない限りデフォルトで作成されるインデックス。
↓「33」というレコードを探索する場合のインデックスのたどり方
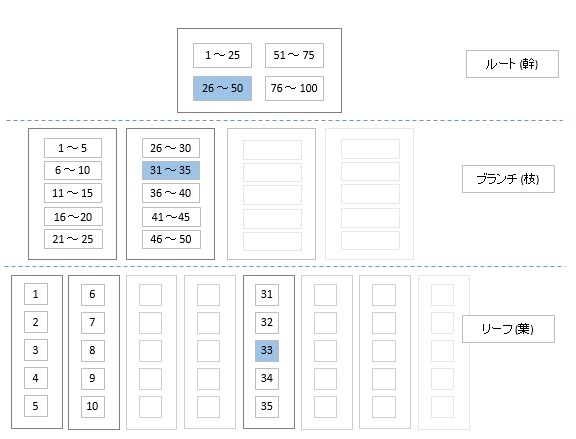
(1)ルートブロック(幹)
(2)ブランチブロック(枝)
(3)リーフブロック(葉)
から成り、上から順に検索される。
(1)ヘッダブロック
キーを発見した後、次にどのブロックを検索するか?が分かる仕組みになっている。
キー値、下層へのポインタを持つ
(2)ブランチブロック
ヘッダブロックと同様、次にどのブロックを検索するか?が分かる仕組みになっている。
キー値、下層へのポインタを持つ。
リーフブロックの1つ上の階層の場合は、行IDを指定する。
(3)リーフブロック
行毎のIDを持つ。
索引による速度向上低下
| 速くなる | 遅くなる | |
|---|---|---|
| 主キー | × | |
| 外部キー | ○ | |
| 表全体のデータ量 | 多い | 少ない |
| 全行の2~4%未満の行の検索 | 多い | 少ない |
| 索引列のデータ範囲 | 広い | 狭い |
| 索引列のWHERE句指定 | 多い | 少ない |
| 表の更新 | 少ない | 多い |
・主キー制約列/Unique制約列は自動的に索引が作成される為ムダ。
・表の更新によって自動的に索引が再作成される為、更新時の速度が低下する。
CREATE INDEX
一意でない(重複する)データを持つ行に対して索引を作成する方法
主キー制約、一意制約を設ける事で自動的に索引は作成される
主キー制約列/一意制約列でないが、一意性がある列に対して索引を作成する場合
CREATE UNIQUE INDEX 索引名 ON 表名(列名, 列名)
・通常は一意制約を付加する
・この場合、重複する値を格納できなくなる(NULLは可)
CREATE CLUSTERED INDEX インデックス名
ON テーブル名(列名)
非クラスター化インデックス作成(デフォルト)
CREATE NONCLUSTERED INDEX インデックス名
ON テーブル名(列名)
ALTER INDEX インデックス名 ON テーブル名(列名) DISABLE
ALTER INDEX インデックス名 ON テーブル名(列名) REBUILD
DROP INDEX
※索引の所有者/DROP ANY INDEX権限保持者 のみ可能
※DROP TABLEの結果、索引も削除される
クラスター化/非クラスター化インデックス
Bツリーインデックスにおけるインデックスの種類
・クラスター化インデックス
テーブルに作成できるインデックス数:1
・非クラスター化インデックス
テーブルに作成できるインデックス数:249
